YLearn与因果推断概述
机器学习近年来取得了巨大的成就。机器学习成功的领域主要在预测方面,比如:分类猫和狗的图片。然而,机器学习不能够回答在许多场景中自然地产生的问题。 一个例子是在策略评估中的 反事实问题:如果策略发生改变,会发生什么?事实上,由于这些反事实不能够被观测到。机器学习模型,预测工具不能够被使用。 机器学习的这些缺点是导致如今因果推断应用的部分原因。
因果推断直接的建模了干涉的结果,并将反事实推理形式化。在机器学习的帮助下,如今,因果推断能够从观察到的数据中以不同的方式得到因果的结论,而不是依靠精心设计的实验。
一个常见的完整的因果推断过程是由三部分组成。首先,它使用叫做因果发现的技术学习因果关系。这些关系将在之后以结构化因果模型或者有向无环图(DAG)的形式表示。 其次,它将根据观测到的数据来表示因果估计量。该因果估计量由感兴趣的因果问题,比如平均治疗效果阐明。这个过程被称为识别。最终,一旦因果估计量被识别了,因果推断将会专注 于从观测到的数据中估计因果估计量。接着,策略评估问题和反事实问题都能够被回答。
YLearn, 配备了许多最近的文献中发展的技术,在机器学习的帮助下,用于支持从因果发现到因故估计量的估计的整个因果推断流程。这尤其在有大量的观测数据时,更有发展前景。
YLearn中的概念和相关的问题设置
在YLearn中,关于因果推断流程有5个主要组成部分。
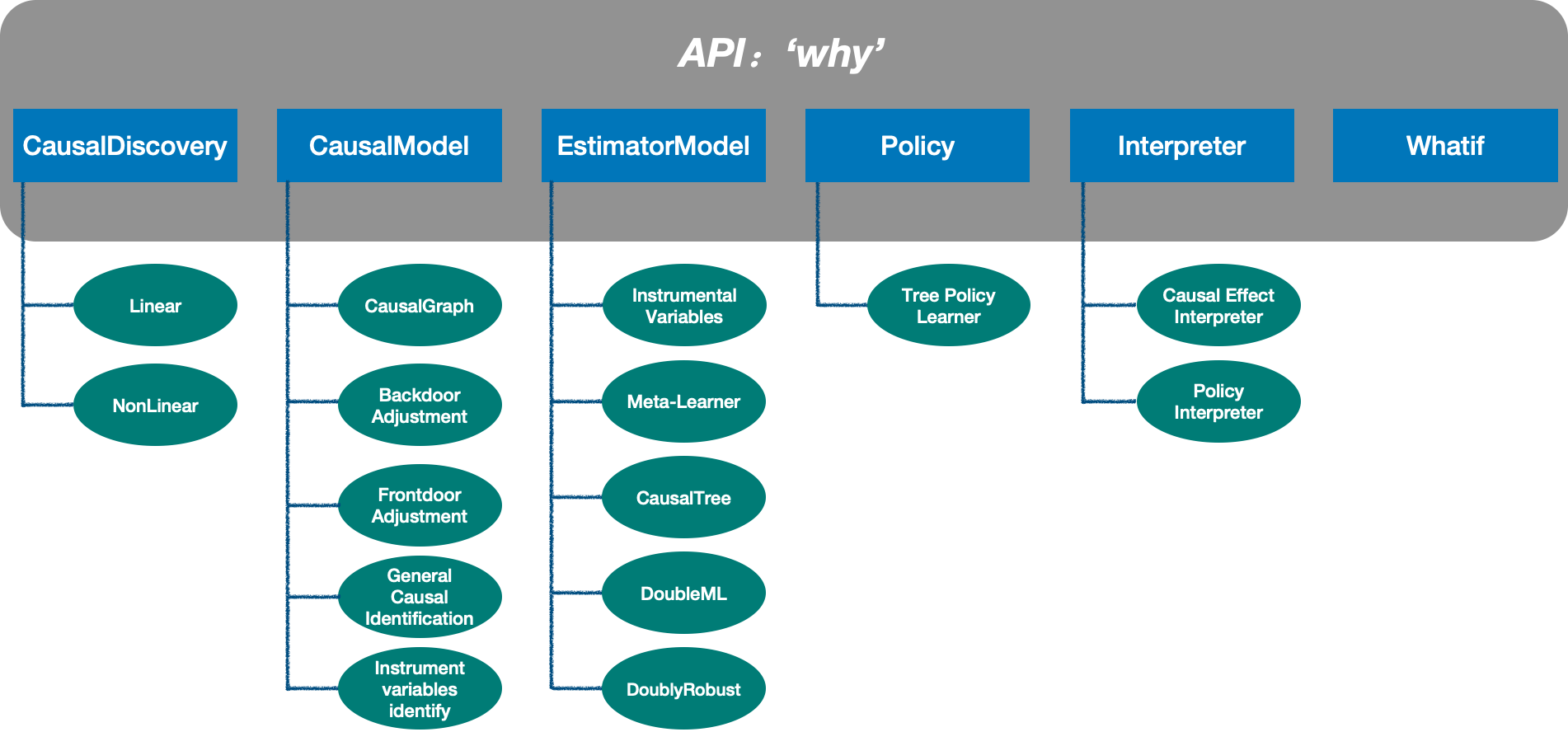
Components in YLearn
因果发现. 在观测数据中发现因果关系。
因果模型. 以
CausalGraph的形式表示因果关系并做其他的相关操作比如用CausalModel识别。估计模型. 使用不同的技术对因果估计量进行估计。
策略模型. 对每一个个体选择最好的策略。
解释器. 解释因果效应和策略。
这些组成部分被连接在一起形成一个完整的因果推断流程,被封装在一个API Why 中。
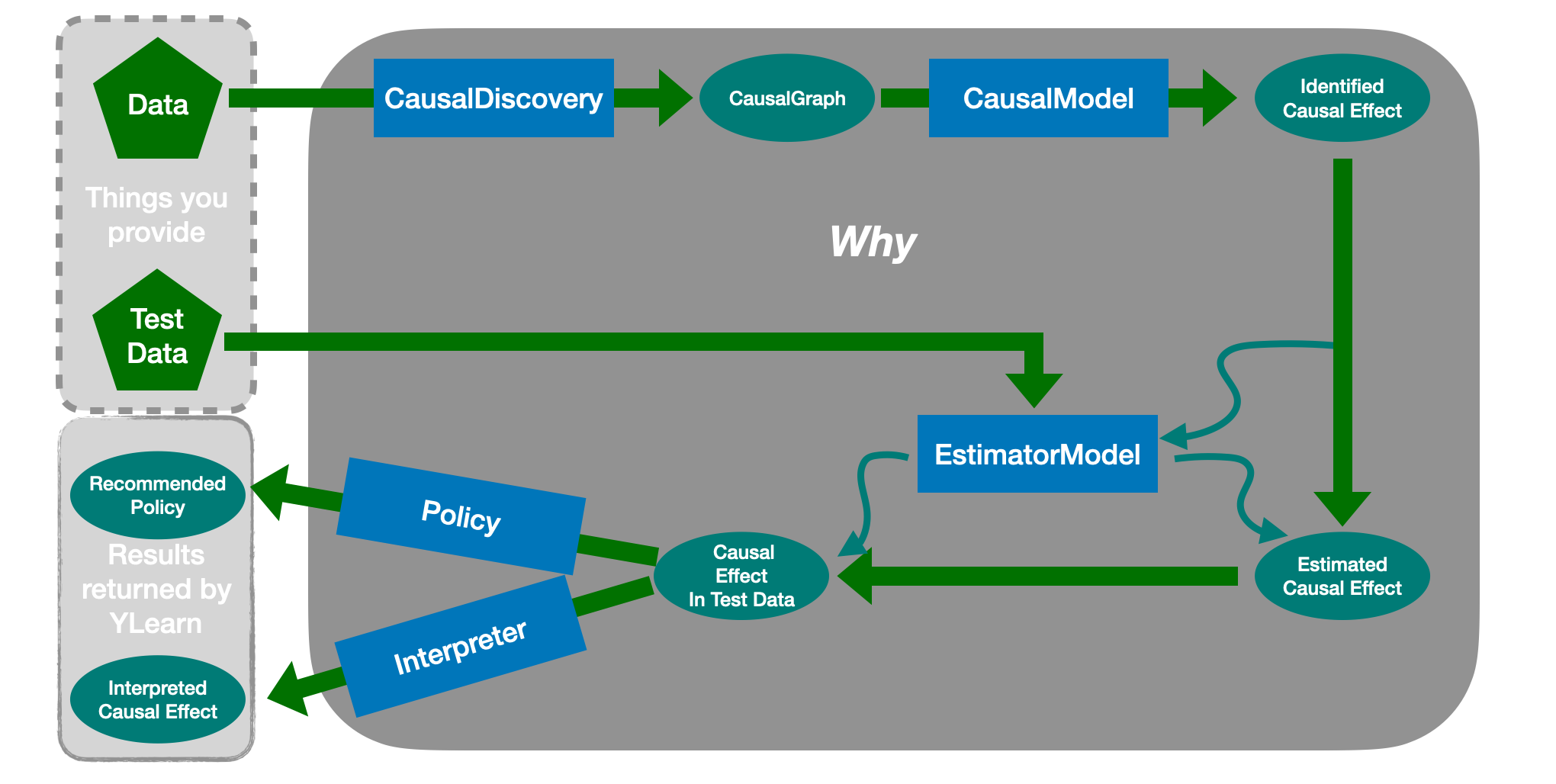
YLearn中因果推断的流程. 从训练数据中, 首先使用 CausalDiscovery 来得到数据中的因果结构,通常输出一个 CausalGraph 。 因果图被传入 CausalModel , 其中,感兴趣的因果效应被识别并转换成统计估计量。一个 EstimatorModel 接着通过训练数据进行训练来建模 因果效应和其他变量之间的关系,等价于估计训练数据中的因果效应。之后,可以使用一个训练过的 EstimatorModel 在一些新的测试数据集上预测因果效应并估计 分配给每个个体的策略或者解释估计的因果效应。
所有的APIs将在 API: 与YLearn交互 中介绍。