Why: 一个一体化的因果学习API
想要轻松使用YLearn?尝试一体化的API Why!
Why 是一个封装了YLearn中几乎所有东西的API,比如 识别因果效应 和 给一个训练好的估计器模型打分。它提供给用户一个简单且有效的方式来使用 我们的包:能够直接传入你仅有的东西,数据到 Why 中并使用它的多个方法,而不是学习多个概念,比如在能够找到藏在你的数据中有趣的信息之前学习调整集合。 Why 被设计成能够执行因果推断的完整流程:给出数据,它首先尝试发现因果图,如果没有提供的话。接着它尝试找到可能作为治疗的变量和识别因果效应。在此之后,一个 合适的估计器模型将被训练用以估计因果效应。最终,估计对于每一个个体最佳的选项的策略。
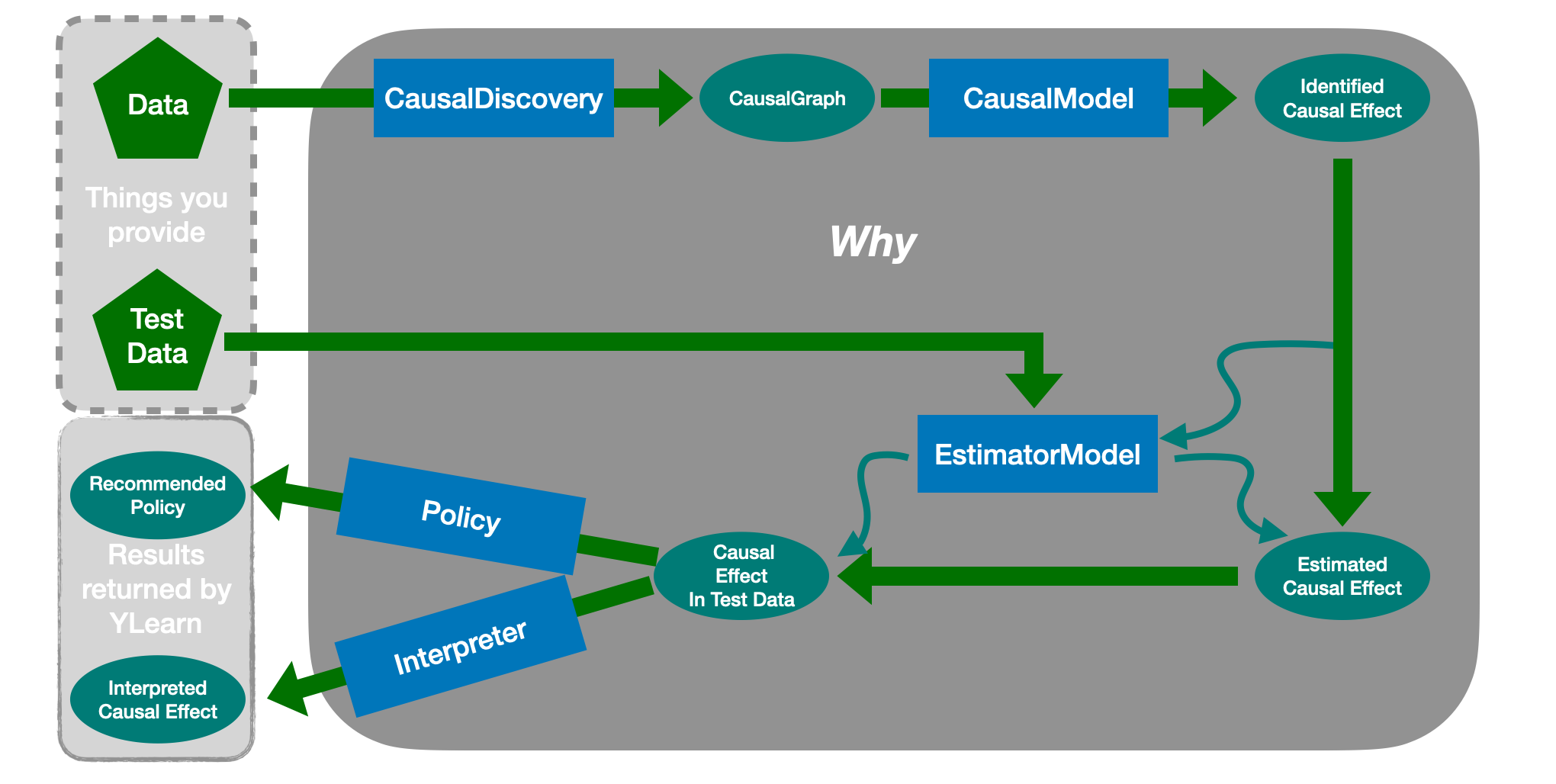
Why 能够帮助因果推断的完整流程的几乎每一个部分。
使用示例
本节我们使用sklearn数据集 california_housing 演示如何使用 Why ,可通过如下代码准备数据集:
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing(as_frame=True)
data = housing.frame
outcome = housing.target_names[0]
data[outcome] = housing.target
其中变量 data 就是我们准备好的数据集。
通过缺省参数使用 Why
最简单的使用 Why 的方式是使用缺省参数创建一个 Why 对象,并且是在 fit 时只提供数据集 data 和输出结果的名称 outcome 。
from ylearn import Why
why = Why()
why.fit(data, outcome)
print('identified treatment:',why.treatment_)
print('identified adjustment:',why.adjustment_)
print('identified covariate:',why.covariate_)
print('identified instrument:',why.instrument_)
print(why.causal_effect())
输出:
identified treatment: ['MedInc', 'HouseAge']
identified adjustment: None
identified covariate: ['AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude']
identified instrument: None
mean min max std
MedInc 0.411121 -0.198831 1.093134 0.064856
HouseAge -0.000385 -0.039162 0.114263 0.005845
通过用户指定的treatment使用Why
在 fit Why 对象时,可通过参数 treatment 设置实际业务所要求的treatment:
from ylearn import Why
why = Why()
why.fit(data, outcome, treatment=['AveBedrms', ])
print('identified treatment:',why.treatment_)
print('identified adjustment:',why.adjustment_)
print('identified covariate:',why.covariate_)
print('identified instrument:',why.instrument_)
print(why.causal_effect())
输出:
identified treatment: ['AveBedrms']
identified adjustment: None
identified covariate: ['MedInc', 'HouseAge', 'AveRooms', 'Population', 'AveOccup', 'Latitude', 'Longitude']
identified instrument: None
mean min max std
AveBedrms 0.197422 -0.748971 10.857963 0.169682
在不fit Why 对象的情况下识别潜在的treatment
我们可以直接调用 Why 对象的 identify 方法识别潜在的treatment、adjustment、covariate和instrument,该方法返回一个由四个元素构成的tuple。
why = Why()
r=why.identify(data, outcome)
print('identified treatment:',r[0])
print('identified adjustment:',r[1])
print('identified covariate:',r[2])
print('identified instrument:',r[3])
输出:
identified treatment: ['MedInc', 'HouseAge']
identified adjustment: None
identified covariate: ['AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude']
identified instrument: None
类结构
- class ylearn._why.Why(discrete_outcome=None, discrete_treatment=None, identifier='auto', discovery_model=None, discovery_options=None, estimator='auto', estimator_options=None, random_state=None)
一个一体化的因果学习API。
- param bool, default=None discrete_outcome:
如果是True则强制将结果看作是离散变量,如果是False则强制将结果看作是连续变量, 如果是None则在fit时自动推断。
- param bool, default=None discrete_treatment:
如果是True则强制将treatment看作是离散变量,如果是False则强制将treatment看作是连续变量, 如果是None则在fit时自动推断。
- param str or Identifier, default=auto’ identifier:
可用的选项: ‘auto’ 或 ‘discovery’ 或 ‘gcastle’ 或 ‘pgm’
- param dict, optional, default=None identifier_options:
参数(键值对)来初始化 identifier
- param str, optional, default=’auto’ estimator:
EstimatorModel的名字。 也可以传入一个合理的估计器模型的实例。
- param dict, optional, default=None estimator_options:
参数(键值对)来初始化估计器模型
- param callable, optional, default=None fn_cost:
成本函数,基于成本对因果效应进行调整。
- param str, default=’effect’ effect_name:
在基于成本对因果效应进行调整时,传递给fn_cost的因果效应在DataFrame中的列名。仅当fn_cost不为None时生效。
- param int, optional, default=None random_state:
随机种子
- feature_names_in_
在 fit 时看到的特征的名字的列表
- outcome_
结果的名字
- treatment_
在 fit 时识别的治疗的名字的列表
- adjustment_
在 fit 时识别的调整的名字的列表
- covariate_
在 fit 时识别的协变量的名字的列表
- instrument_
在 fit 时识别的工具的名字的列表
- identifier_
identifier 对象或者None。用于识别治疗/调整/协变量/工具,如果在 fit 时没有被指明
- y_encoder_
LabelEncoder 对象或者None。当outcome是类别型时,对outcome进行编码.
- preprocessor_
在 fit 时预处理数据的`Pipeline` 对象
- estimators_
对于每个治疗的估计器字典,其中键是治疗的名字,值是 EstimatorModel 对象
- fit(data, outcome, *, treatment=None, adjustment=None, covariate=None, instrument=None, treatment_count_limit=None, copy=True, **kwargs)
拟合Why对象,包括如下步骤:
如果outcome不是数值型变量的话,则对其进行编码(LabelEncoder)
识别treatment、adjustment、covariate和instrument
如果treatment是离散变量的话,则对其进行编码(LabelEncoder)
预处理数据
拟合因果估计器
- 参数:
data (pandas.DataFrame, required) – 拟合用的数据集
outcome (str, required) – 输出结果outcome的名称.
treatment (list of str, optional) – treatment名称列表。如果是str类型则会补被尝试用逗号分隔成列表;如果是None的话则Why会尝试自动识别潜在的treatment。
adjustment (list of str, optional) – adjustment名称列表。如果是str类型则会补被尝试用逗号分隔成列表;如果是None的话则Why会尝试自动识别潜在的adjustment。
covariate (list of str, optional) – covariate名称列表。如果是str类型则会补被尝试用逗号分隔成列表;如果是None的话则Why会尝试自动识别潜在的covariate。
instrument (list of str, optional) – instrument名称列表。如果是str类型则会补被尝试用逗号分隔成列表;如果是None的话则Why会尝试自动识别潜在的instrument。
treatment_count_limit (int, optional) – 自动识别时treatment的个数限制,缺省是 min(5, 特征总数的10%)。
copy (bool, default=True) – 是否创建data的数据复本。
- 返回:
拟合的
Why对象。- 返回类型:
Why
- identify(data, outcome, *, treatment=None, adjustment=None, covariate=None, instrument=None, treatment_count_limit=None)
识别潜在的treatment、adjustment、covariate和instrument。
- 返回:
识别的treatment、adjustment、covariate和instrument
- Rtypes:
tuple
- causal_graph()
获得识别的因果图。
- 返回:
识别的因果图
- 返回类型:
CausalGraph的实例
- causal_effect(test_data=None, treatment=None, treat=None, control=None, target_outcome=None, quantity='ATE', return_detail=False, **kwargs)
估计因果效应。
- 参数:
test_data (pandas.DataFrame, optional) – 用于评估因果效应的数据集。如果是None的话则使用fit时的数据集。
treatment (str or list, optional) – treatment名称或列表。应当是属性 treatment_ 的子集。缺省是属性 **treatment_**的所有元素。
treat (treatment value or list or ndarray or pandas.Series, default None) – 对于单个离散的treatment,treat应当是treatment所有可能值中的一个;对于多个离散的treatment,treat应当是由每个treatment的值组成的一个列表(list);对于连续性treatment,treat应当是与test_data行数相同的ndarray或pandas.Series。缺省是None,由Why自行推断。
control (treatment value or list or ndarray or pandas.Series, default None) – 与treat类似。
target_outcome (outcome value, optional) – 仅当outcome是离散型是生效。缺省是属性 y_encoder_.classes_ 中的最后一个元素。
quantity (str, optional, default 'ATE', optional) – ‘ATE’ or ‘ITE’, 缺省是 ‘ATE’。
return_detail (bool, default False) – 是否在返回结果中包括因果效应的详细数据(detail)
- 返回:
- 所有治疗的因果效应。当quantity=’ATE’时,返回结果的DataFrame包括如下列:
mean: 因果效应的均值
min: 因果效应的最小值
max: 因果效应的最大值
detail (当 return_detail=True时 ): 以ndarray表示的因果效应的详细数据。
当quantity=’ITE’时,返回结果是由个体因果效应组成的DataFrame。
- 返回类型:
pandas.DataFrame
- individual_causal_effect(test_data, control=None, target_outcome=None)
为每一个个体估计因果效应。
- 参数:
test_data (pandas.DataFrame, optional) – 用于评估因果效应的数据集。如果是None的话则使用fit时的数据集。
control (treatment value or list or ndarray or pandas.Series, default None) – 对于单个离散的treatment,control应当是treatment所有可能值中的一个;对于多个离散的treatment,control应当是由每个treatment的值组成的一个列表(list);对于连续性treatment,control应当是与test_data行数相同的ndarray或pandas.Series。缺省是None,由Why自行推断。
target_outcome (outcome value, optional) – 仅当outcome是离散型是生效。缺省是属性 y_encoder_.classes_ 中的最后一个元素。
- 返回:
对于每一个治疗,个体的因果效应。
- 返回类型:
pandas.DataFrame
- whatif(test_data, new_value, treatment=None)
获得反事实预测当治疗从它的对应的观测变为new_value。
- 参数:
test_data (pandas.DataFrame, required) – 用于反事实预测的数据集。
new_value (ndarray or pd.Series, required) – 与test_data行数相同的新的值。
treatment (str, default None) – treatment名称。缺省使用 treatment_ 的第一个元素。
- 返回:
反事实预测结果
- 返回类型:
pandas.Series
- score(test_data=None, treat=None, control=None, scorer='auto')
- 返回:
估计器模型的分数
- 返回类型:
float
- policy_interpreter(test_data, treatment=None, control=None, target_outcome=None, **kwargs)
获得策略解释器
- 参数:
test_data (pandas.DataFrame, required) – 用于评估的数据集。
treatment (str or list, optional) – treatment名称,缺省是 treatment_ 的前两个元素。
control (treatment value or list or ndarray or pandas.Series) – 对于单个离散的treatment,control应当是treatment所有可能值中的一个;对于多个离散的treatment,control应当是由每个treatment的值组成的一个列表(list);对于连续性treatment, control应当是与test_data行数相同的ndarray或pandas.Series。缺省是None,由Why自行推断。
target_outcome (outcome value, optional) – 仅当outcome是离散型是生效。缺省是属性 y_encoder_.classes_ 中的最后一个元素。
kwargs (dict) – 用于初始化PolicyInterpreter的参数。
- 返回:
拟合的
PolicyInterpreter的实例。- 返回类型:
PolicyInterpreter的实例
- uplift_model(test_data, treatment=None, treat=None, control=None, target_outcome=None, name=None, random=None)
获取uplift model(针对一个treatment)
- param pandas.DataFrame, required test_data:
The test data to evaluate.
- param str or list, optional treatment:
Treatment name. If str, it should be one of the fitted attribute treatment_. If None, the first element in the attribute treatment_ is used.
- param treatment value, optional treat:
缺省是treatment对应的编码器的 classes_ 的最后一个值。
- param treatment value, optional control:
缺省是treatment对应的编码器的 classes_ 的第一个值。
- param outcome value, optional target_outcome:
仅当outcome是离散型是生效。缺省是属性 y_encoder_.classes_ 中的最后一个元素。
- param str name:
Lift名称。缺省使用treat值。
- param str, default None random:
随机生成数据的Lift名称,缺省不生成随机数据。
- returns:
The fitted instance of
UpliftModel.- rtype:
instance of
UpliftModel
- plot_causal_graph()
绘制因果关系图。
- plot_policy_interpreter(test_data, treatment=None, control=None, **kwargs)
绘制解释器。