Why: An All-in-One Causal Learning API
Want to use YLearn in a much easier way? Try the all-in-one API Why!
Why is an API which encapsulates almost everything in YLearn, such as identifying causal effects and scoring a trained estimator model. It provides to users a simple and efficient way to use our package: one can directly pass the only thing you have, the data, into Why and call various methods of it rather than learning multiple concepts such as adjustment set before being able to find interesting information hidden in your data. Why is designed to enable the full-pipeline of causal inference: given data, it first tries to discover the causal graph if not provided, then it attempts to find possible variables as treatments and identify the causal effects, after which a suitable estimator model will be trained to estimate the causal effects, and, finally, the policy is evaluated to suggest the best option for each individual.
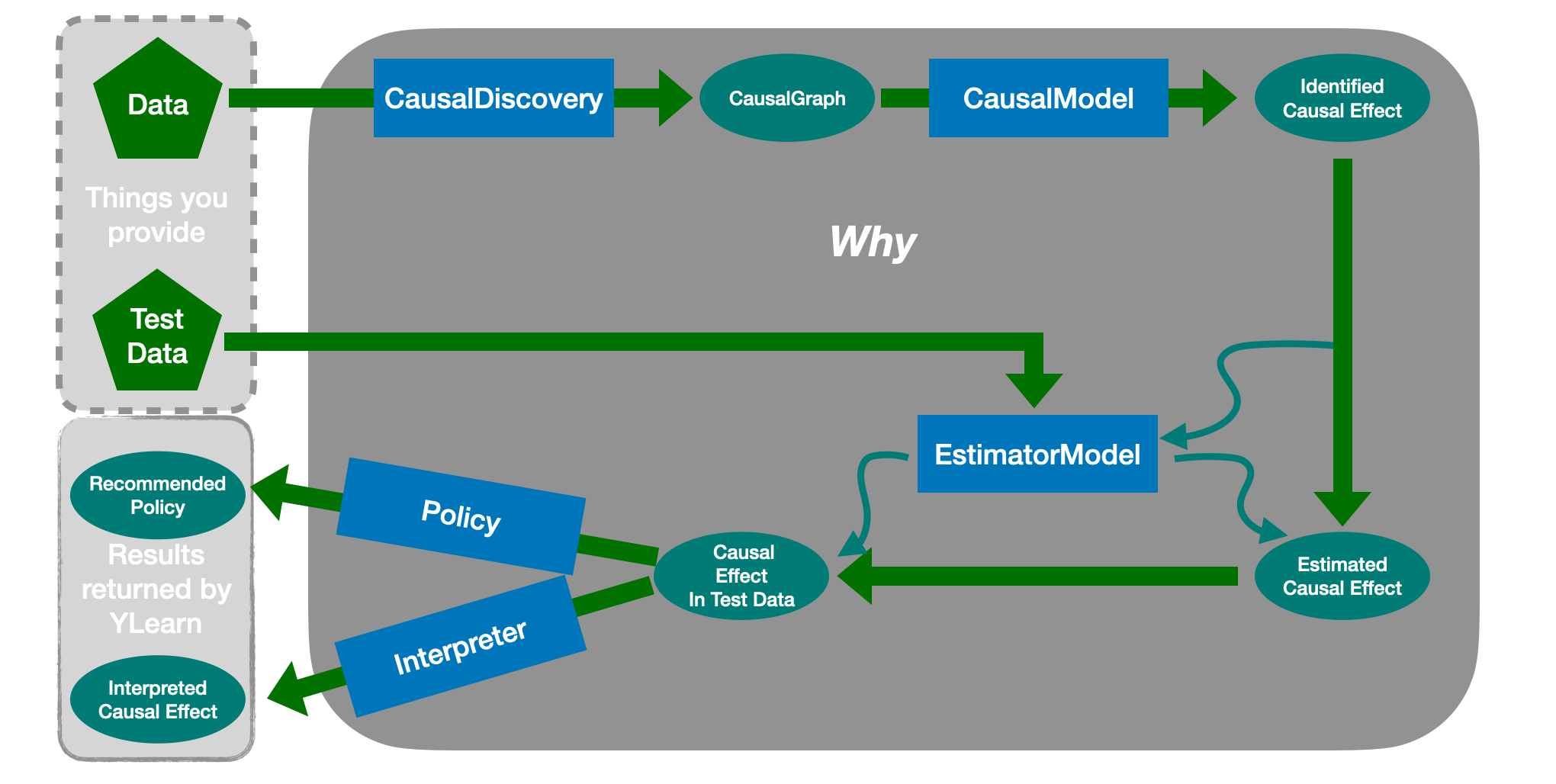
Why can help almost every part of the whole pipeline of causal inference.
Example usages
In this chapter, we use dataset california_housing to show how to use Why. We prepare the dataset with code below:
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing(as_frame=True)
data = housing.frame
outcome = housing.target_names[0]
data[outcome] = housing.target
The variable data is our prepared dataset.
Fit Why with default settings
The simplest way to use Why is creating Why instance with default settings and fit it with training data and outcome name only.
from ylearn import Why
why = Why()
why.fit(data, outcome)
print('identified treatment:',why.treatment_)
print('identified adjustment:',why.adjustment_)
print('identified covariate:',why.covariate_)
print('identified instrument:',why.instrument_)
print(why.causal_effect())
Outputs:
identified treatment: ['MedInc', 'HouseAge']
identified adjustment: None
identified covariate: ['AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude']
identified instrument: None
mean min max std
MedInc 0.411121 -0.198831 1.093134 0.064856
HouseAge -0.000385 -0.039162 0.114263 0.005845
Fit Why with customized treatments
We can fit Why with argument treatment to specify the desired features as treatment.
from ylearn import Why
why = Why()
why.fit(data, outcome, treatment=['AveBedrms', ])
print('identified treatment:',why.treatment_)
print('identified adjustment:',why.adjustment_)
print('identified covariate:',why.covariate_)
print('identified instrument:',why.instrument_)
print(why.causal_effect())
Outputs:
identified treatment: ['AveBedrms']
identified adjustment: None
identified covariate: ['MedInc', 'HouseAge', 'AveRooms', 'Population', 'AveOccup', 'Latitude', 'Longitude']
identified instrument: None
mean min max std
AveBedrms 0.197422 -0.748971 10.857963 0.169682
Identify treatment without fitting Why
We can call Why’s method identify to identify treatment, adjustment, covariate and instrument without fitting it.
why = Why()
r=why.identify(data, outcome)
print('identified treatment:',r[0])
print('identified adjustment:',r[1])
print('identified covariate:',r[2])
print('identified instrument:',r[3])
Outputs:
identified treatment: ['MedInc', 'HouseAge']
identified adjustment: None
identified covariate: ['AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude']
identified instrument: None
Class Structures
- class ylearn._why.Why(discrete_outcome=None, discrete_treatment=None, identifier='auto', identifier_options=None, estimator='auto', estimator_options=None, random_state=None)
An all-in-one API for causal learning.
- Parameters
discrete_outcome (bool, default=None) – If True, force the outcome as discrete; If False, force the outcome as continuous; If None, inferred from outcome.
discrete_treatment (bool, default=None) – If True, force the treatment variables as discrete; If False, force the treatment variables as continuous; if None, inferred from the first treatment
identifier (str or Identifier, default=auto') – If str, available options: ‘auto’ or ‘discovery’ or ‘gcastle’ or ‘pgm’
identifier_options (dict, optional, default=None) – Parameters (key-values) to initialize the identifier
estimator (str, optional, default='auto') – Name of a valid EstimatorModel. One can also pass an instance of a valid estimator model.
estimator_options (dict, optional, default=None) – Parameters (key-values) to initialize the estimator model
fn_cost (callable, optional, default=None) – Cost function, used to readjust the causal effect based on cost.
effect_name (str, default='effect') – The column name in the argument DataFrame passed to fn_cost. Effective when fn_cost is not None.
random_state (int, optional, default=None) – Random state seed
- feature_names_in_
list of feature names seen during fit
- outcome_
name of outcome
- treatment_
list of treatment names identified during fit
- adjustment_
list of adjustment names identified during fit
- covariate_
list of covariate names identified during fit
- instrument_
list of instrument names identified during fit
- identifier_
identifier object or None. Used to identify treatment/adjustment/covariate/instrument if they were not specified during fit
- y_encoder_
LabelEncoder object or None. Used to encode outcome if it is discrete.
- preprocessor_
Pipeline object to preprocess data during fit
- estimators_
estimators dict for each treatment where key is the treatment name and value is the EstimatorModel object
- fit(data, outcome, *, treatment=None, adjustment=None, covariate=None, instrument=None, treatment_count_limit=None, copy=True, **kwargs)
Fit the Why object, steps:
encode outcome if its dtype is not numeric
identify treatment and adjustment/covariate/instrument
encode treatment if discrete_treatment is True
preprocess data
fit causal estimators
- Parameters
data (pandas.DataFrame, required) – Training dataset.
outcome (str, required) – Name of the outcome.
treatment (list of str, optional) – Names of the treatment. If str, will be split into list with comma; if None, identified by identifier.
adjustment (list of str, optional, default=None) – Names of the adjustment. Identified by identifier if adjustment/covariate/instrument are all None.
covariate (list of str, optional, default=None) – Names of the covariate. Identified by identifier if adjustment/covariate/instrument are all None.
instrument (list of str, optional, default=None) – Names of the instrument. Identified by identifier if adjustment/covariate/instrument are all None.
treatment_count_limit (int, optional) – maximum treatment number, default min(5, 10% of total feature number).
copy (bool, default=True) – Set False to perform inplace transforming and avoid a copy of data.
- Returns
The fitted
Why.- Return type
instance of
Why
- identify(data, outcome, *, treatment=None, adjustment=None, covariate=None, instrument=None, treatment_count_limit=None)
Identify treatment and adjustment/covariate/instrument without fitting Why.
- Parameters
data (pandas.DataFrame, required) – Training dataset.
outcome (str, required) – Name of the outcome.
treatment (list of str, optional) – Names of the treatment. If str, will be split into list with comma; if None, identified by identifier.
adjustment (list of str, optional, default=None) – Names of the adjustment. Identified by identifier if adjustment/covariate/instrument are all None.
covariate (list of str, optional, default=None) – Names of the covariate. Identified by identifier if adjustment/covariate/instrument are all None.
instrument (list of str, optional, default=None) – Names of the instrument. Identified by identifier if adjustment/covariate/instrument are all None.
treatment_count_limit (int, optional) – maximum treatment number, default min(5, 10% of the number of features).
- Returns
tuple of identified treatment, adjustment, covariate, instrument
- Rtypes
tuple
- causal_graph()
Get identified causal graph.
- Returns
Identified causal graph
- Return type
instance of
CausalGraph
- causal_effect(test_data=None, treatment=None, treat=None, control=None, target_outcome=None, quantity='ATE', return_detail=False, **kwargs)
Estimate the causal effect.
- Parameters
test_data (pandas.DataFrame, optional) – The test data to evaluate the causal effect. If None, the training data is used.
treatment (str or list, optional) – Treatment names, should be subset of attribute treatment_, default all elements in attribute treatment_
treat (treatment value or list or ndarray or pandas.Series, default None) – In the case of single discrete treatment, treat should be an int or str of one of all possible treatment values which indicates the value of the intended treatment; in the case of multiple discrete treatment, treat should be a list where treat[i] indicates the value of the i-th intended treatment, for example, when there are multiple discrete treatments, list([‘run’, ‘read’]) means the treat value of the first treatment is taken as ‘run’ and that of the second treatment is taken as ‘read’; in the case of continuous treatment, treat should be a float or a ndarray or pandas.Series, by default None
control (treatment value or list or ndarray or pandas.Series, default None) – This is similar to the cases of treat, by default None
target_outcome (outcome value, optional) – Only effective when the outcome is discrete. Default the last one in attribute y_encoder_.classes_.
quantity (str, optional, default 'ATE', optional) – ‘ATE’ or ‘ITE’, default ‘ATE’.
return_detail (bool, default False) – If True, return effect details in result.
kwargs (dict, optional) – Other options to call estimator.estimate().
- Returns
- causal effect of each treatment. When quantity=’ATE’, the result DataFrame columns are:
mean: mean of causal effect,
min: minimum of causal effect,
max: maximum of causal effect,
detail (if return_detail is True ): causal effect ndarray;
in the case of discrete treatment, the result DataFrame indices are multiindex of (treatment name and treat_vs_control); in the case of continuous treatment, the result DataFrame indices are treatment names. When quantity=’ITE’, the result DataFrame are individual causal effect of each treatment, in the case of discrete treatment, the result DataFrame columns are multiindex of (treatment name and treat_vs_control); in the case of continuous treatment, the result DataFrame columns are treatment names.
- Return type
pandas.DataFrame
- individual_causal_effect(test_data, control=None, target_outcome=None)
Estimate the causal effect for each individual.
- Parameters
test_data (pandas.DataFrame, required) – The test data to evaluate the causal effect.
control (treatment value or list or ndarray or pandas.Series, default None) – In the case of single discrete treatment, control should be an int or str of one of all possible treatment values which indicates the value of the intended treatment; in the case of multiple discrete treatment, treat should be a list where control[i] indicates the value of the i-th intended treatment, for example, when there are multiple discrete treatments, list([‘run’, ‘read’]) means the treat value of the first treatment is taken as ‘run’ and that of the second treatment is taken as ‘read’; in the case of continuous treatment, treat should be a float or a ndarray or pandas.Series, by default None
target_outcome (outcome value, optional) – Only effective when the outcome is discrete. Default the last one in attribute y_encoder_.classes_.
- Returns
individual causal effect of each treatment. The result DataFrame columns are the treatment names; In the case of discrete treatment, the result DataFrame indices are multiindex of (individual index in test_data, treatment name and treat_vs_control); in the case of continuous treatment, the result DataFrame indices are multiindex of (individual index in test_data, treatment name).
- Return type
pandas.DataFrame
- whatif(test_data, new_value, treatment=None)
Get counterfactual predictions when treatment is changed to new_value from its observational counterpart.
- Parameters
test_data (pandas.DataFrame, required) – The test data to predict.
new_value (ndarray or pd.Series, required) – It should have the same length with test_data.
treatment (str, default None) – Treatment name. If str, it should be one of the fitted attribute treatment_. If None, the first element in the attribute treatment_ is used.
- Returns
The counterfactual prediction
- Return type
pandas.Series
- score(test_data=None, treat=None, control=None, scorer='auto')
Scoring the fitted estimator models.
- Parameters
test_data (pandas.DataFrame, required) – The test data to score.
treat (treatment value or list or ndarray or pandas.Series, default None) – In the case of single discrete treatment, treat should be an int or str of one of all possible treatment values which indicates the value of the intended treatment; in the case of multiple discrete treatment, treat should be a list where treat[i] indicates the value of the i-th intended treatment, for example, when there are multiple discrete treatments, list([‘run’, ‘read’]) means the treat value of the first treatment is taken as ‘run’ and that of the second treatment is taken as ‘read’; in the case of continuous treatment, treat should be a float or a ndarray or pandas.Series, by default None
control (treatment value or list or ndarray or pandas.Series) – This is similar to the cases of treat, by default None
scorer (str, default 'auto') – Reserved.
- Returns
Score of the estimator models
- Return type
float
- policy_interpreter(test_data, treatment=None, control=None, target_outcome=None, **kwargs)
Get the policy interpreter
- Parameters
test_data (pandas.DataFrame, required) – The test data to evaluate.
treatment (str or list, optional) – Treatment names, should be one or two element. default the first two elements in attribute treatment_
control (treatment value or list or ndarray or pandas.Series) – In the case of single discrete treatment, control should be an int or str of one of all possible treatment values which indicates the value of the intended treatment; in the case of multiple discrete treatment, control should be a list where control[i] indicates the value of the i-th intended treatment, for example, when there are multiple discrete treatments, list([‘run’, ‘read’]) means the control value of the first treatment is taken as ‘run’ and that of the second treatment is taken as ‘read’; in the case of continuous treatment, control should be a float or a ndarray or pandas.Series, by default None
target_outcome (outcome value, optional) – Only effective when the outcome is discrete. Default the last one in attribute y_encoder_.classes_.
kwargs (dict) – options to initialize the PolicyInterpreter.
- Returns
The fitted instance of
PolicyInterpreter.- Return type
instance of
PolicyInterpreter
- uplift_model(test_data, treatment=None, treat=None, control=None, target_outcome=None, name=None, random=None)
Get uplift model over one treatment.
- Parameters
test_data (pandas.DataFrame, required) – The test data to evaluate.
treatment (str or list, optional) – Treatment name. If str, it should be one of the fitted attribute treatment_. If None, the first element in the attribute treatment_ is used.
treat (treatment value, optional) – If None, the last element in the treatment encoder’s attribute classes_ is used.
control (treatment value, optional) – If None, the first element in the treatment encoder’s attribute classes_ is used.
target_outcome (outcome value, optional) – Only effective when the outcome is discrete. Default the last one in attribute y_encoder_.classes_.
name (str) – Lift name. If None, treat value is used.
random (str, default None) – Lift name for random generated data. if None, no random lift is generated.
- Returns
The fitted instance of
UpliftModel.- Return type
instance of
UpliftModel
- plot_causal_graph()
Plot the causal graph.
- plot_policy_interpreter(test_data, treatment=None, control=None, **kwargs)
Plot the interpreter.
- Returns
The fitted instance of
PolicyInterpreter.- Return type
instance of
PolicyInterpreter